13.3. Gargalo de acesso
Sistemas modernos frequentemente precisam acessar dados de uma maneira incrívelmente rápida. Por exemplo, grandes servidores de FTP e HTTP podem manter milhares de sessões ao mesmo tempo e podem ter multiplas conexões de 100 Mbit/s com o mundo externo, bem além das taxas de transmisão da maioria dos discos.
Os discos atuais podem transferir dados sequencialmente em até 70 MB/s, mas este valor é de pouca importância em um ambiente onde muitos processos independentes acessam um disco, onde eles talvez atinjam apenas uma fração desse valor. Nesses casos é mais importante observar o problema do ponto de vista do subsystem: o parametro importante é a carga que uma transferência coloca no subsystem, em outras palavras, o tempo em que a transferência ocupa os discos envolvidos.
Em qualquer operação de transferência, o disco deve primeiramente posicionar as cabeças de leitura e esperar até que o primeiro setor passe em baixo delas e depois sim executar a transferência. Esses atos podem ser considerados com se fossem atômicos: não faz o menor sentido interromper eles.
Considere uma transferência típica de aproximadamente 10 kB: a geração atual de discos de alta performance podem posicionar as cabeças em uma média de 3.5 ms. Os discos mais rápidos giram em 15.000 rpm, então, a rotação latente média (metade de uma revolução) é de 2 ms. Em 70 MB/s, a transferência propriamente dita, leva em torno de 150 μs, o que é quase nada comprado com o tempo de posicionamento. Em tal caso, a taxa efetiva de transferência fica um pouco maior que 1 MB/s e é altamente dependente no tamanho do que vai ser transferido, é claro.
A solução óbvia e tradicional para esse gargalo é ``more spindles'': ele usa vários discos pequenos com a mesma capacidade de armazenamento em vez de usar um outro disco grande. Cada disco é capaz de se posicionar e transferir dados de maneira independente, então o ritmo de transferência efetivo, cresce a uma taxa próxima ao número de discos usados.
O ritmo de transferência exato é, claramente, menor que o número de discos envolvidos: apesar de cada disco ser capaz de relizar transferencias em paralelo, não existe nenhuma forma de se assegurar que as solicitações estão distribuidas de maneira uniforme entre os discos. Inevitavelmente a carga no disco será maior do que no outro.
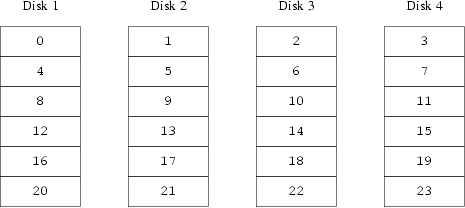
A distribuição equilibrada da carga nos discos é fortemente dependente do modo em que os dados são compartilhados entre eles. No próximo debate, seria conveniente visualizar um disco como se fosse um grande número de setores de dados mapeados por números, como as páginas de um livro. O método mais simples seria dividir o disco virtual em pequenos grupos de setores consecutivos do tamanho do disco físico individual e depois armzená-los desse jeito, semelhante a pegar um livro grande e dividí-lo em pequenas sessões. Esse étodo é chamado de concatenação e tem a vantagem que os discos não precisam ter nenhum tipo de relacionamento quanto a tamanho. Funciona bem quando o acesso ao disco virtual é dividido de maneira igual entre os seus espaços mapeados. Quando o acesso é concentrado uma área menor, o aumento no desempenho é menos acentuado. A Figura 13-1 ilustra a seqüência na qual as unidades de armazenamento são alocadas em uma organização concatenada.
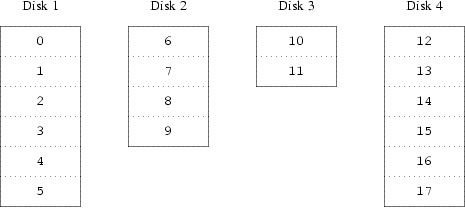
Um mapeamento alternativo é dividir o espaço de endereçamento em componentes menores, de tamanhos iguais e armazená-los seqüencialmente em discos diferentes. Por exemplo, os primeiros 256 setores poderiam ser armazenados no primeiro disco, os 256 setores seguintes no próximo disco e assim por diante. Depois de preencher o último disco o processo se repete até que os discos estejam cheios. Esse mapemento é chamado de striping ou RAID-0. [1]. O striping exige um esforço grande para localizar os dados e isso causa carga adicional de I/O onde a tranferência é distribuida para diversos discos, mas pode também fornecer uma carga constante entre os discos. Figura 13-2 ilustra uma seqüência em que as unidades de armazenamento são alocadas em uma organização striped.